As part of the computer vision domain, the perception system in autonomous vehicles naturally becomes a stage where Convolutional Neural Networks (CNNs) shine. This is the eighth article in our series on unmanned technology, and it provides an in-depth exploration of CNNs, focusing on their application in 3D sensing and object detection for autonomous systems.
Introduction to CNN
Convolutional Neural Networks (CNNs) are a type of deep neural network specifically designed to process continuous input signals such as images, video, and audio. The concept was first inspired in 1968 by Hubel and Wiesel's research on the visual cortex of animals, which revealed the principles of directional selectivity and translational invariance—principles that later earned them a Nobel Prize. Fast forward to the 1980s, as neural network research advanced, scientists began to recognize the similarity between convolution operations in images and the way biological neurons process local inputs. This led to the development of the convolution operation as a fundamental component of CNNs.
Compared to traditional deep neural networks (DNNs), CNNs have several key features:
- High-level neurons only receive input from a localized region in the lower layer, typically a rectangular area, mimicking the receptive field concept found in biological neural networks.
- Weights in the same layer are shared across different positions, leveraging translational invariance to reduce model parameters and accelerate training.
Due to its specialized design for visual data, CNN has become the go-to architecture in computer vision. In 2012, CNN made a breakthrough in the ImageNet competition, drastically changing the landscape of image recognition. From then on, traditional methods were replaced by CNN-based models. As a core component of computer vision, autonomous vehicle perception relies heavily on CNNs to understand and interpret the 3D environment around them.
Unmanned Binocular 3D Perception
In autonomous driving, accurately modeling the surrounding 3D environment is critical. While LiDAR sensors provide high-precision point clouds, they often lack detailed texture information. Cameras, on the other hand, can capture rich visual details but struggle with depth estimation. Inspired by human binocular vision, stereo cameras use two viewpoints to infer depth. Using basic geometry, the distance to a point P can be calculated based on the baseline B, the disparity d, and the focal length f of the camera.
To estimate the depth z, we need to calculate the disparity d using the left and right images I_l and I_r. A common approach is to match local regions between the two images. However, since individual pixel values may be unreliable, we assume smoothness in the disparity map, leading to a minimization problem. This is similar to optical flow estimation, where the current frame and the next frame replace the left and right images.
MC-CNN
Now let’s take a closer look at the Matching-Cost CNN (MC-CNN), an algorithm that uses CNNs to compute the matching cost between two images. The network structure of MC-CNN is shown in Figure 1.
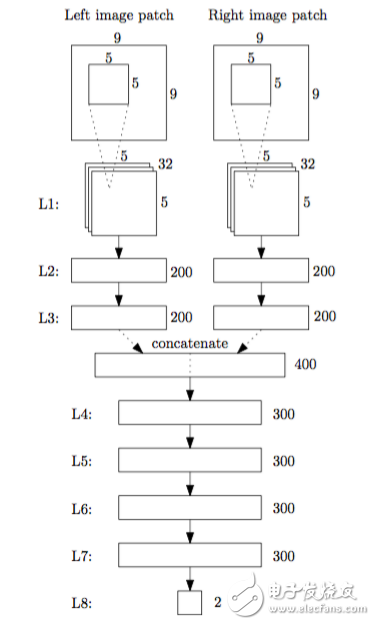
The input consists of small image patches from both the left and right cameras, and the output is a probability score indicating how well the two patches match. When the patches match perfectly, the score is 0; when they don’t match, the score approaches 1. By searching for the minimum output value for each position, we can estimate the disparity d. Afterward, the results are refined through post-processing steps such as:
- **Cross-based cost aggregation**: Averaging disparities of nearby pixels with similar intensity values to improve stability.
- **Semi-global matching**: Applying smoothing constraints to ensure consistency between neighboring points.
- **Interpolation and border correction**: Filling gaps and refining the final disparity map.
The effectiveness of the MC-CNN algorithm is illustrated in Figure 2.

While MC-CNN effectively computes matching costs, it still requires additional processing to refine the disparity map. Can we integrate all these steps into a single CNN? FlowNet does exactly that, demonstrating the power of end-to-end learning in 3D perception tasks.
Toshiba Adapter
High efficient charging speed for Toshiba laptop, stable current outlet can offer power for the laptop at the same time charge the laptop battery. The best choice for your replacement adapter. We can meet your specific requirement of the products, like label design. The plug type is US/UK/AU/EU. The material of this product is PC+ABS. All condition of our product is 100% brand new.
Our products built with input/output overvoltage protection, input/output overcurrent protection, over temperature protection, over power protection and short circuit protection. You can send more details of this product, so that we can offer best service to you!
Toshiba Adapter,Adapter For Toshiba,Power Supply For Toshiba,Laptop Charger For Toshiba
Shenzhen Waweis Technology Co., Ltd. , https://www.waweis.com