The generation of confrontation networks has always been an important tool for deep learning. After several years of development, GANs has also derived many different models, such as DCGANs, Wasserstein GANs, BEGANs and so on. This article will explore the application of conditional GAN ​​(Conditional GANs) in image generation.
Conditional GANs have been applied to a variety of image-related tasks, but the resolution is usually not high and looks unreal. In this paper, researchers at NVI and the University of California at Berkeley have proposed a new method for synthesizing high-resolution streetscapes. The 2048x1024 images generated from semantic tag mapping using conditional GANs are not only more visually appealing, but also New counter-loss losses and new multi-scale generator and discriminator architectures have been generated.
Synthesize instance level image
The next step is the specific experimental process of the project. First, it is the use of the baseline algorithm pix2pix. Pix2pix is ​​a conditional GAN ​​framework for image translation, which includes a generation network G and a discrimination network D. In this task, the goal of generating the network G is to translate the semantic tag mapping into a near real image, and the goal of discriminating the network D is to compare the generated image with the real image.
Pix2pix uses U-Net as the generation network, while using the underlying convolutional network as the discriminator. However, the image resolution generated by the dataset Cityspaces is only 256x256, so that the training process is very unstable, and the quality of the generated image is not very good, so the pix2pix framework needs to be improved.
The researchers switched the generation network to a coarse-to-fine network and used a multi-scale discriminant network structure. At the same time, a stable anti-learning objective function is adopted.
Coarse-to-fine generator
The researchers divided the generation network into two parts: the global generation network G1 and the local enhancement network G2. The acceptable resolution of the globally generated network G1 is 1024x512, and the image resolution of the local enhanced network output is 4 times that of the previous image. If you still want a higher composite image, you can continue to add a local enhancement network.
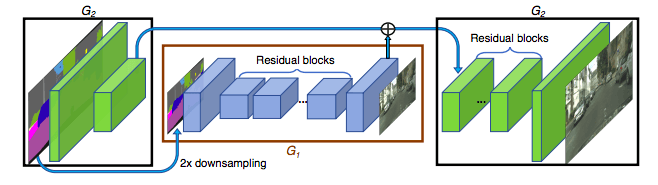
Generating network structure
Multi-scale discriminators
For the GAN discriminant network, high-resolution images are no small challenge. In order to distinguish between true HD pictures and composite pictures, the discriminating network requires a huge receiving field. So this requires a deeper network or a larger convolution kernel. But both methods increase the network's ability and can lead to overfitting. And they require a larger storage script when training, which is rare for high-resolution image generation.
To solve this problem, the researchers proposed a method using a multi-scale discriminator, that is, using three networks with the same structure, but running against images of different sizes. A network that can handle the largest size has the largest receive area, which can guide the generation network to generate an overall more coordinated image. Handling the smallest size network can lead the generation network to be handled more carefully in detail.
Loss function
Researchers extract features from multiple layers of the authentication network and learn to match these intermediate representations from real and synthetic images. For convenience of representation, we will identify the i-th layer of the network Dk as Dk(i), and the feature matching loss LFM(G, Dk) as:
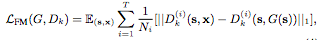
Where T is the total number of layers and Ni is the constituent element of each layer.
The function that ultimately combines GAN loss and feature matching loss is expressed as:
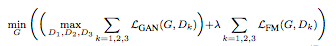
Where λ controls the importance of both.
Existing image synthesis methods use only semantic tag mapping, where each pixel value represents the object class to which the pixel belongs. This mapping does not distinguish between objects of the same category. On the other hand, the instance level semantic tag mapping includes a unique ID for each individual object. An easy way to include an instance map is to pass it directly to the network or encode it into a single vector. However, since different images may contain different numbers of objects of the same category, both methods are difficult to implement in practice.
So we chose to use instance mapping, which provides object boundaries that are not in the semantic tag map. For example, when multiple objects of the same category are adjacent to each other, only viewing the semantic tag mapping cannot distinguish them.
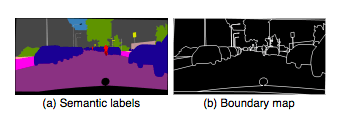
The figure below shows a model trained with instance boundary mapping with sharper image boundaries.

Comparative Results
In order to quantify the quality of the composite image, the researchers segmented it semantically and compared the degree of matching between the predicted portion of the prediction and the input portion. As can be seen from the table below, the method we use is far superior to the other methods and is very close to the original image.

On the CityScapes dataset, our method is still better than the other two methods without loss function.

On the NYU dataset, the images generated by our method look more realistic than the images generated by other methods.

Other results:
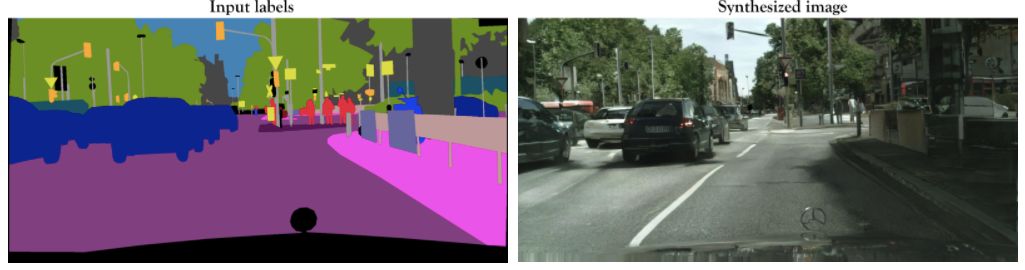
Input label (left) and composite image (right)

After zooming in, you can see that the details of the objects in the figure are clearer.

In the experiment of the ADE20K dataset, the results generated by our results are almost the same as the original image.

Experiments on the Helen Face dataset allow users to change facial features in real time on an interactive interface. Such as changing skin color, adding a beard, etc.
You can draw your own "masterpiece" on the website: uncannyroad.com/
Conclusion
The experimental results show that the conditional GANs can synthesize high-resolution realistic images without manually adjusting the loss function or training the network in advance. Our results will help many areas that require high-resolution images but do not have pre-trained networks, such as medical imaging and biology.
At the same time, this paper shows us that the image-to-image composite pipeline can be used to generate a variety of results. Researchers believe that these results will help expand the range of applications for image synthesis.
120W Medical Power Supply,120W Medical Device Power Supply,120W Medical Power Adapter,120W Rade Power Supplies
Shenzhen Longxc Power Supply Co., Ltd , https://www.longxcpower.com